POSTGRESQL 是一个对象关系型数据库,由来自全球一组网络开发者开发。它是一个可代替如Oracle、Informix商业数据库的开源版本。
POSTGRESQL 最初由加州大学伯克利分校开发。1996年,一个小组开始在互联网上开发该数据库。他们使用email分享想法,用文件服务器分享代码。POSTGRESQL现在在功能方面、性能方面以及可靠性上可与商业数据库比肩。它支持事务、视图、存储过程和参考完整性约束。它也支持大量的编程接口,包括ODBC、Java(JDBC)、TCL/TK、PHP、Perl以及Python。得益于互联网开发者人才库,POSTGRESQL 还有广阔的增长空间。
性能概念
数据库性能优化有两个方面。一方面是提高数据库对电脑CPU,内存和硬盘的使用。另一方面是最优化传递到数据库的查询。这篇文章讨论的是在硬件方面优化数据库性能。通过使用例如:CREATE INDEX,VACUUM,VACUUM FULL,ANALYZE,CLUSTER和EXPLAIN这些数据库SQL命令,插叙查询的最优化已经完成了。这些在我写的《PostgreSQL:Introduction and Concepts》(http://momjian.us/main/writings/pgsql/aw_pgsql_book/)这本书中已经讨论过了。
为了理解硬件性能的问题,就必须理解在电脑的内部发生了什么。简单的说,一台电脑可以被视为一个被存储器包围的中央处理单元(CPU)。在和CPU同一小片上的是不同的寄存器,它们保存了中间运算结果和各种指针以及计数器。包围这些的是CPU cache,其中有最新的访问信息。越过CPU cache是大量的随机存取存储器(RAM),它保存了正在运行的程序以及数据。在RAM的外围就是硬盘了,它保存了更加多的信息。硬盘是唯一可以永久存储信息的区域。,所以电脑关机后,所有被保存下来的信息都在这里。归纳起来,这些是包围CPU的存储区域:
\includegraphics[height=0.25\textheight]{caches}
存储区域 容量
CPU寄存器 几字节
CPU高速缓存 几千字节
RAM 几兆字节
硬盘 几千兆字节
你可以看到储存大小随着离CPU距离的增加而增加。理论上,大容量的永久存储可以被安置在CPU的旁边,但是这将变的很慢而且很昂贵。实际当中,最常用的信息被放在CPU的旁边,而不怎么用的信息就放得离CPU远远的。在CPU需要的时候再拿给CPU。
缩短数据与 CPU 的距离
数据在各种存储区域的转移是自动执行的。编译器决定哪些数据存在寄存器里头。CPU 决定哪些数据存在缓存里面。 操作系统负责内存和硬盘之间的数据交换。
数据库管理员对 CPU 的寄存器和缓存无能为力。要提高数据库的性能,只能通过增加内存中的有用数据量, 从而减少磁盘访问来获得。
看似简单, 其实不然, 内存中的数据包含很多东西:
正在执行中的程序
程序的数据和堆栈
POSTGRESQL 共享缓存
内核磁盘缓存
内核
理想的性能调整, 既要增加内存中的数据库数据占有量,又不能对系统造成负面影响。
POSTGRESQL 共享缓存
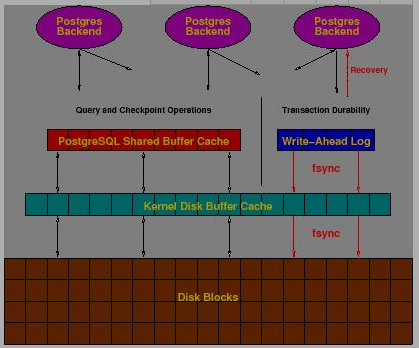
POSTGRESQL 没有直接访问磁盘,而是访问 POSTGRESQL 的缓存。然后再由 POSTGRESQL 的后台程序读写这些数据块, 最后写到磁盘上。
后台首先在表中,查找缓存是否已经存在这些数据。 有, 就继续处理。没有, 则由操作系统从内核磁盘缓存, 或者直接从磁盘加载这些数据。无论哪一种,代价都很高。
POSTGRESQL 默认分配 1000 个缓存。每个缓存有 8k 字节。增加缓存的数量,能增加后台访问缓存的频率,减少代价较高的系统请求。缓存的数量,可以通过 postmaster 命令行的参数, 或者配置文件 postgresql.conf 中的 shared_buffers 的值来设置。
多大才算太大?

你可能在想, “那我把所有的内存都分配给 POSTGRESQL 的缓冲区好了”。 如果你这么做, 那系统内核以及其他程序就没有内存可用了。理想的 POSTGRESQL 共享缓冲区大小,是在没有对系统产生不利影响的情况下, 越大越好。
要理解什么是不利影响,首先要明白 UNIX 是如何管理内存的。要是内存容量足够大,能容下所有的程序和数据。 那我们也就用不着管理内存了。问题是, 内存的容量有限,所以, 需要内核将内存中的数据分页, 存入磁盘,这就是传说的的数据交换。原理是, 将当前用不上的数据移到磁盘中。这个操作叫做交换区页面移入(swap pageout)。页面移入交换区不难,只要在程序非活跃期执行就可以。问题在于, 页面重新从交换区移出来的时候。 也就是, 移到交换区的旧页面, 又重新移回内存。这个操叫交换区移出( swap pagein)。说它是个问题, 是因为, 当页面移入内存的时候, 程序需要终止执行, 直到移入操作完成。
系统的页面移入活跃情况, 可以通过像 vmstatand sar 这种系统分析工具来查看, 是否有足够的内存, 维持系统的正常运作。不要把交换区页面移出,跟常规的页面移出搞混了。常规的页面移出, 将页面数据从文件系统中读出来,当作是系统操作的一部分。如果你看不出, 是否有交换区页面移出操作。但是交换区页面移入的操作非常活跃, 这也说明,有大量的页面移出的操作正在进行。
高速缓存(cache)容量的影响
或许你会想为什么高速缓存的大小如此重要。首先,试想一下PostgreSQL共享缓存大到可以放下整张表。重复连续扫描这张表就不需要硬盘的参与,因为数据已经在cache里了。现在假设cache比表小一个单元。一次连续的扫描将会把所有单元载入cache直到最后一个单元。当需要最后一个单元时,最初的单元被移除。当另一次连续扫描开始的时候,最初的单元已经不再cache里了,为了载入它,最开始的单元会被移除,也就是第一次扫描时的第二个单元会被移除。这将持续进行到单元结束。这个例子很极端,但是你可以看到减少一个单元就将会把cache的效率从100%变为0%。这表明找到合适的cache容量会戏剧性的改变性能。
合适容量的共享缓存
理论上,POSTGERSQL共享缓存将是:
它应该足够大来应付通常的表访问操作。
它应该足够小来避免 swap pagein 的发生。
记住数据库管理器运行时分配所有的共享存储。这一区域即使在没有访问数据库的请求时也保持一样大小。一些操作系统pageout未指定的共享存储,而另一些LOCK共享存储到RAM中。LOCK贡献存储更好一点。P OSTGERSQL的管理员指导手册里有关于不同操作系统核心配置的信息, http://developer.postgresql.org/docs/postgres/kernel-resources.html。
批量排序的内存规模
另一项能调节性能的参数是, 用做批量排序的内存容量。当对大量数据排序时, POSTGRESQL 会将他们拆分成许多小的数据块进行排序。然后将中间结果存在临时文件里面。这些文件最终被合并,重新排序,直到所有的数据行的排序完毕。增加批量处理的内存规模, 能减少临时文件的数量。从而提高排序速度。不过, 如果批量处理的规模设置太大, 会导致交换区的分页操作变得更频繁。这种情况下,使用大量临时文件的小规模批量排序速度比较快。所以, 由交换区分页活跃程度, 决定内存是不是被过量分配。记住, 这个参数是给后台执行排序用的。如: ORDER BY, CREATE INDEX,或者数据合并。有几个并行排序任务, 就需要几倍这样的内存容量。
这个参数的值, 可以通过 postmaster 命令行参数, 或者配置文件 postgresql.conf 中的 sort_mem 来设置。
缓存规模和排序规模
缓存规模和排序规模都会影响内存的使用。你不可能增加一个的规模, 而不影响另外一个。记住,缓存的规模是在 postmaster 启动的时候, 就设好的。 而排序的规模择由排序的数量决定。一般情况下,缓存规模要大过排序的规模。不过, 某些用到 ORDER BY, CREATE INDEX 或数据合并的查询, 可以通过加大排序规模来提速。
此外, 许多操作系统对共享内存的分配有限制。修改这一限制, 就意味着, 要重新编译或者配置内核。也就是说, 你要对操作系统这方面相当熟练才行。更多信息, 参考 POSTGRESQL 管理员操作手册,http://developer.postgresql.org/docs/postgres/kernel-resources.html.
在调整的开始,使用15%的RAM作为缓存大小,如果有几个大的事物就用2-4%的内存做排序大小,如果你有很多小事物的话就使用更小的内存。你可以尝试提高它来看看性能是否提升,swapping交换是否发生。如果共享缓存过大,你就花费太多时间来维护大量的缓存,而且它会浪费掉本可以被其他进程使用的RAM,无法作为额外的内核磁盘的缓存。
有价值的服务器参数是effective_cache_size。这个参数被优化器用来估计内核磁盘缓存的大小。在使用统一缓存的内核里,这个值应该设为内核未使用RAM的平均值,因为这样内核就可以使用未使用的RAM来缓存最近访问的磁盘页。在有固定磁盘缓存的内核里,这个值应该设为内核缓存的大小,一般为RAM的10%。
Disk Locality

磁盘本身的特点, 决定了他的性能跟上面提到的其他存储方式不同。别的存储方式, 访问数据中的任何一个字节, 速度都是一样的。 而磁盘,由于磁盘片在不断的转动, 磁头在不断的移动,访问离磁头当前位置近的数据, 速度要比离磁头远的数据快。
磁头从一个柱面, 移动到同一个磁盘片的另外一个柱面, 比较耗时间。Unix 内核开发人员当然知道这一点。所以在磁盘上存储大文件的时候,他们尽可能把同一个文件的存储块紧挨在一起存放。例如:我们有一个文件, 在磁盘上保存, 需要占10个存储块。操作系统会把 1-5 存储块放在一个柱面, 而 6-10 存在另外一个柱面。从头到尾读取这个文件, 只需要磁头移动两次 -- 一次移到存放 1-5 存储块的柱面, 另外一次移到存放 6-10 那个柱面。但是, 如果文件的读取不按存储块的顺序来,比如 1,6,2,7,3,8,4,9,5,10, 那么读完整个文件就要移动磁头十次。 所以, 对于磁盘来说,按顺序访问要比随机访问快的多。这也是为什么, POSTGRESQL 在读取表中的大量数据时, 宁可选择顺序扫描, 也不用索引扫描。 磁盘的这个缺点, 让我们看到了缓存的价值。
多磁盘
数据库操作期间, 磁头会频繁移动. 太多的读/写请求, 会导致磁盘队列饱和, 性能急剧下降. (我们可以通过 Vmstat 和 sar 这两种工具, 查看磁盘的活动情况 )
其中一个解决磁盘队列饱和的办法是, 将部分 POSTGRESQL 数据文件移到其他磁盘. 注意, 别把文件移到同一个磁盘的其他文件系统. 因为同一个磁盘上的所有文件系统共享一个磁头.