高级编程语言提供的函数、条件语句和循环这样的抽象编程构造极大地提高了编程效率。然而,这也潜在地使性能显著下降成为了用高级编程语言写程序的一大劣势。在理想条件下,在不以性能为妥协的情况下,你应该写出易读并且易维护的代码。因此,编译器尝试自动优化代码以提高其性能,当今的编译器都深谙其道。编译器可以转化循环、条件语句和递归函数、消除整块代码和利用目标指令集的优势让代码变得高效而简洁。所以对程序员来说,写出可读性高的代码要比因为手工优化而使代码变得神秘且难以维护更加可贵。事实上,手工优化的代码反而可能会让编译器难以进行额外和更加有效的优化。
比起手工优化代码,你更应该考虑关于设计的各个方面,比如使用更快的算法,引入线程级并行机制和利用框架特性(比如move构造函数)。
这篇文章是关于Visual C++ 编译器优化的。为了便于应用,我将会讨论编译器采取的最重要的优化技巧和决策。我的目的不是告诉你如何手工优化代码,而是向你展示为什么你可以信赖编译器来优化你写出的代码。这篇文件绝不是对Visual C++ 编译器优化工作的全面考察。但是将会给你展示那些你真正想要了解的优化工作和怎样与你的编译器沟通来应用它们。
有一些重要的优化是超出所有现有编译器能力的——比如,用高效的算法代替低效的,或者改变数据结构的排列以优化其在内存中的布局。但是这些优化话题超出了本文的范围。
定义编译器优化
优化工作涉及到的一个方面,是把一行代码转化成同等效果的另一行代码,在这个过程中提升它的一项或多项性能。最重要的两项性能(指标)是代码的执行速度和长度。其他一些特性包括代码执行开销,代码编译所需时间,如果代码需要通过即时编译机制(Just-in-Time (JIT))进行编译,那么JIT所需的编译时间也是指标之一。
编译器经常会依据它们所使用的技术优化代码。虽然并不完美,但是比起花时间手工苦苦推敲一个程序,利用编译器提供的特有功能和让编译器来优化代码要高效得多。
这里有4种方法让你的编译器更加高效地优化代码:
书写可读、高效的代码。不要把Visual C++ 面向对象的特性当作性能的敌人。最新版本的C++可以让这些开销保持到最低甚至消除这些开销。
2.使用编译器声明。例如让编译器使用比默认情况更快的函数调用约定。
3.使用编译器内置函数(compiler-intrinsic functions)。内在函数是其实现由编译器自动提供的特殊函数。编译器对其很熟悉并且会用极其高效的指令序列来代替函数调用,以充分利用目标指令集的优势。当前Microsoft .NET Framework不支持编译器内置函数,因此其下的语言都不支持。但是Visual C++ 对这一特性有外在支持。注意,虽然使用内置函数能够提升代码性能,但是会降低可读性和可移植性。
4. 使用性能分析引导优化(profile-guided optimization)。使用这一技术,可以让编译器搜集更多关于代码的运行时行为,并且以此来作为优化依据。
本文的目的是通过证明编译器可以在低效但是可读性强的代码上应用优化(应用第一条方法),从而向你展示为什么你可以信任编译器。当然我也会提供一些对性能分析引导优化(profile-guided optimization)的简短说明,和提到一些可以微调代码的编译器声明。
编译器有许多优化技巧,从像常量折叠这样简单的变换,直到像指令重排(instruction scheduling)这样极其复杂的变换。然而在这篇文章中我只有限地讨论了一些最重要的优化——那些可以显著地提升性能(两位数的百分数来衡量)和减少代码长度的优化:内联函数(function inlining)、COMDAT优化(COMDAT optimizations)和循环优化。我将会在下一部分讨论前两个话题,然后展示你如何控制Visual C++实现优化。最后会有.NET Framework优化的简略说明。通篇我都将会采用Visual Studio 2013来构建代码。
链接时代码生成
链接时代码生成(LTCG)是一项应用在C/C++代码上的程序全局优化(WPO)技术。C/C++编译器独立地编译每个源文件然后产生出相应的目标文件。这意味着编译器只能在单个源文件上应用优化技术,而无法照顾到整个程序。但是,一些重要的优化却只能浏览全部程序后才能产生。所以你只能在链接时(link time)应用这些优化,而非编译时(compile time),因为链接器可以完整地看到程序。
当LTGC被打开时(通过指定编译器开关/GL),编译器驱动程序(cl.exe)将只调用编译器前端(c1.dll or c1xx.dll),并把后端调用(c2.dll)推迟到链接时间。产出的目标文件包含通用中间语言(Common Intermediate Language——CIL)代码,而不是依赖机器的汇编代码。然后,当链接器(link.exe)被调用,它就能看到包含C中间语言的目标文件,并调用编译器后端,依次进行程序全局优化,生成二进制目标文件,再返回链接器把所有目标文件链接在一起,最后生成可执行文件。
编译器前端实际上进行了一些优化,比如无论优化启用还是禁用,都会进行常量折叠。但是所有重要的优化工作都是在编译器后端进行的,并且可以使用编译器开关控制。
链接时代码生成(LTCG)能让后端积极地执行许多优化(通过指定/GL与/O1或/O2,以及/Gw编译器开关,和/OPT:REF 与 /OPT:ICF链接器开关)。在本文中,讨论仅限于内联函数(function inlining)和COMDAT优化(COMDAT optimizations)。关于完整的链接时代码生成优化,请参考相关文档。注意链接器可以在本地目标文件,本地/托管混合目标文件,纯托管目标文件,安全托管目标文件和安全.net模块上执行链接时代码生成。
我编写了一个包含两个源文件(source1.c 和 source2.c)和一个头文件(source2.h)的程序。source1.c 和 source2.c分别在Figure 1 and Figure 2中。由于头文件中非常简单地包含了source2.c中的函数原型, 所以并没有列出。
Figure 1 The source1.c File
#include <stdio.h> // scanf_s and printf.
#include "Source2.h"
int square(int x) { return x*x; }
main() {
int n = 5, m;
scanf_s("%d", &m);
printf("The square of %d is %d.", n, square(n));
printf("The square of %d is %d.", m, square(m));
printf("The cube of %d is %d.", n, cube(n));
printf("The sum of %d is %d.", n, sum(n));
printf("The sum of cubes of %d is %d.", n, sumOfCubes(n));
printf("The %dth prime number is %d.", n, getPrime(n));
}
Figure 2 The source2.c File
#include <math.h> // sqrt.
#include <stdbool.h> // bool, true and false.
#include "Source2.h"
int cube(int x) { return x*x*x; }
int sum(int x) {
int result = 0;
for (int i = 1; i <= x; ++i) result += i;
return result;
}
int sumOfCubes(int x) {
int result = 0;
for (int i = 1; i <= x; ++i) result += cube(i);
return result;
}
static
bool isPrime(int x) {
for (int i = 2; i <= (int)sqrt(x); ++i) {
if (x % i == 0) return false;
}
return true;
}
int getPrime(int x) {
int count = 0;
int candidate = 2;
while (count != x) {
if (isPrime(candidate))
++count;
}
return candidate;
}
source1.c文件包含两个函数,有一个参数并返回这个参数的平方的square函数,以及程序的main函数。main函数调用source2.c中除了isPrime之外的所有函数。source2.c有5个函数。cube返回一个数的三次方;sum函数返回从1到给定数的和;sumOfcubes返回1到给定数的三次方的和;isPrime用于判断一个数是否是质数;getPrime函数返回第x个质数。我省略掉了容错处理因为那并非本文的重点。
这些代码简单但是很有用。其中一些函数只进行简单的运算,一些需要简单的循环。getPrime是当中最复杂的函数,包含一个while循环且在循环内部调用了也包含一个循环的isPrime函数。我将会利用这些函数证实被称作内联函数的优化,和一些其他的优化,其中内联函数这是编译器最重要的优化之一。
我会在三种不同的配置下生成代码并且检验结果来验证代码是如何被编译器转化的。如果你也照做的话,你需要汇编生成文件(由编译器开关/FA[s]生成)来检验生成的汇编代码以及映像文件(由链接器开关/MAP生成)来检验初始化数据优化是否被执行(如果你指定了/verbose:icf 和 /verbose:ref开关,链接器也可以汇报这一项)。因此你需要确保在接下来的配置中指定了上述开关。我也会使用C编译器(/TC)以让生成的代码容易检验。但是这篇文章中所有我讨论的东西对于C++一样适用。
Debug配置
之所以使用Debug配置,是因为在你打开了编译器/Od开关而没有打开/GL开关时,所有的后端优化都是禁用的。当在这项配置下构建代码时,生成的目标文件将包含和源代码完全对应的二进制代码。你可以通过生成的汇编输出文件和映像文件来确认这一点。这项配置相当于Visual Studio中的调试配置。
编译时代码生成Release配置
这项配置和优化被启用的配置(通过指定/O1,/O2或/Ox编译器开关)非常相似,但是不指定/GL编译器开关。在这项配置下,生成目标文件将包含优化过的二进制代码。但是没有整个程序级别的优化。
通过查看source1.c生成的汇编代码文件,你会看到执行了两项优化。首先,通过在编译时的评估计算把square函数的第一次调用完全删去了。这是如何发生的呢?编译器发现square函数很小,它应该被作为内联函数。将它作为内联函数之后,编译器发现本地变量n的值是已知的并且在给它赋值和调用函数之间没有发生改变。因此,编译器总结出执行乘法和用25替代结果是安全的。第二项优化,对于square的第二次调用square(m),也被当作内联函数。但是,因为m的值在编译时是未知的,所以编译器不能对计算估值,所以事实上代码被保留了。
现在我会检查source2.c的汇编代码文件,这将会更有趣。在函数sumOfCubes内对cube的调用被作为内联函数。这会让编译器启用了对循环来说意义重大的一些优化(如你在“循环优化”部分将看到的)。此外,SSE2指令集被用于在isPrime函数中,当调用了sqrt函数时把int转化为double而在sqrt返回值时又把double转化为int。并且sqrt只在循环开始前调用了一次。注意如果/arch编译器开关没有被打开,x86编译器将会默认使用SSE2。大多数x86处理器以及所有x86-64处理器,都支持SSE2。
链接时代码生成Release配置
链接时代码生成(LTCG) Relase配置与Visual Studio中的Release配置相同。在这项配置中,优化被启用并且/GL编译器开关被打开。这个开关隐含的指定了使用/O1或者/O2。这告诉编译器生成通用中间语言(Common Intermediate Language——CIL)目标文件而不是汇编目标文件。这样,链接器像之前所说那样调用编译器的后端来执行整个程序的优化。现在我将会讨论一些程序全局优化来展示链接时代码生成带来的巨大好处。这项配置所生成的汇编代码列表可以在网络上得到。
只要允许函数被内联(/Ob控制,不论何时,只要需要优化就可以打开),不论/Gy开关(稍后讨论)是否打开,/GL开关都允许把其他翻译单元中定义的函数作为内联函数。/LTCG链接器开关是可选的并且只为链接器提供指导。
通过查看source1.c的汇编代码,你会看到除了scanf_s之外的所有函数都被作为了内联函数。因此,编译器被允许执行函数cube,sum和sunOfCubes的计算。只有isPrime函数没有被作为内联函数。但是,如果它被我们手动在getPrime中写为内联函数,编译器仍然会在main函数中把getPrime作为内联函数。
正如你所见,将函数内联很重要不仅仅是因为它总是优化函数调用,而且它可以允许编译器进行许多其他优化。将函数内联通常会以代码量增加为代价来提升性能。过度地使用这一优化会导致我们熟知的代码膨胀现象。在每一次调用函数的地方,编译器都会分析这样做的利弊来决定是否将一个函数作为内联函数。
由于内联的重要性,Visual C++编译器提供了比对内联的标准规定控制更多的支持。你可以通过使用auto_inline编译控制编译器不将一段范围内的函数内联。你可以通过标记为__declspec(noinline)控制编译器不把特定的函数或方法内联。你可以用关键字inline标记一个函数来给编译器提示将这个函数作为内联函数(虽然编译器可能选择忽略这一标记如果这次内联带来的是净损失)。inline关键字从C++的第一个版本——C99,就可以使用了。你可以同时在C或者C++中使用微软特有的关键字_inline,这在你使用不支持inline的老式C版本时是很有用的。并且,你可以使用__forceinline关键字(C和C++)来强制编译器将任何可以内联的函数内联。最后但是很重要的一点是,你可以告诉编译器以确定或者不确定的深度拆开一个递归函数,这可以通过使用inline_recursion编译指令来达成。注意编译器当下没有提供任何特性可以让你在函数调用时控制内联,一切都只能在函数定义时控制。
默认情况下生效的/Ob0开关会完全禁用内联功能。你应该在调试代码时使用这一开关(它在Visual Studio Debug配置下是自动打开的)。/Ob1开关让编译器只在函数被定义为inline,__inline 或者__forceinline时,才考虑将函数内联。/Ob2开关在指定了/O[1|2|x]时生效,编译器将会考虑所有的函数是否可以内联。在我看来,只有在/Ob1控制内联时考虑是否使用inline或_inline才是有意义的。
在一些特定的条件下,编译器是不能将函数内联的。举个例子,当虚调用一个虚函数时,因为编译器不知道哪个函数将会被调用,所以这个函数不能被内联。另一个例子是当通过指针调用一个函数而不是通过函数名时。你应该尽力避免这些条件来使得函数可以被内联。具体请参考MSDN文档,那里列出了不能被内联的完整条件列表。
某些优化,当其作用于整个程序级别时,往往比其作用于局部时更加有效,函数内联就是这种类型的优化之一。事实上,大多数优化都在整体级别更加有效。在这一部分余下的内容中,我将会讨论被称作COMDAT优化的一类特定优化。
默认情况下,当编译翻译单元时,所有的代码都被存储到结果目标文件的一个单独区块。链接器在单独区块的范畴上进行操作:也就是对这些区块进行移除、合并或者重新排序。(但是)这种会妨碍链接器进行三项优化工作,而这三项优化工作对显著减少可执行代码量和提升性能又非常重要。第一项是消除未被引用的函数和全局变量;第二项是合并相同的函数和全局常量;第三项是重新对函数和全局变量排序,使得那些在同一路径上执行的函数和被一起访问的变量在物理内存中离得更近,这会让程序有更好的局部性。
为了能让这些链接器优化生效,你可以通过分别打开/Gy(函数级别链接)和/Gw(全局数据优化)来分别让编译器对位于在不同区块的函数和变量进行打包操作。这些区块被称为COMDATs。你也可以用__declspec( selectany)标记特定的全局数据变量来告诉编译器把这个变量加入COMDAT。然后,通过指定/OPT:REF链接器开关,链接器就会删去未被引用的函数和全局变量。你也可以通过指定/OPT:ICF开关,链接器就会合并相同的函数和全局常数变量。(ICF代表Identical COMDAT Folding。)通过/ORDER链接器开关,你可以让链接器把COMDAT以特定的顺序放入生成镜像。注意所有的这些优化都是链接器优化所以不需要/GL开关。如果是要对程序进行调试,并且目的明确,那么/OPT:REF和/OPT:ICF开关应当关闭。
你应该尽可能使用链接时代码生成(LTCG)。唯一不使用的原因是当你想要分发生成的目标文件和二进制文件时。记得这些文件包含通用中间语言(CIL)而不是汇编语言,通用中间语言只能被生成它的特定版本的编译器和链接器识别,这将会明显限制目标文件的使用,因为开发者必须使用相同版本的编译器以使用这些文件。这种情况下,除非你愿意为每个版本的编译器都分发一份目标文件,否则你应该使用编译时代码生成。除了限制使用,这些目标文件通常比相应的汇编目标文件更加庞大。但是记得CIL目标文件带来的巨大好处,那就是可以进行程序全局优化(WPO)。
循环优化
Visual C++支持多种循环优化,但是我只讨论其中的3种:循环展开,自动向量化和循环不变量代码移动。如果你修改了Figure1中的代码让m代替n作为sumOfCubes的参数,编译器将不能推断出参数的值,所以必须让函数可以处理任何参数。生成函数被高度优化并且尺寸很大,所以编译器不会将它作为内联函数。
用/O1生成汇编代码,会在空间尺寸上进行优化。在这种情况下,不会对sumOfCubes函数实行任何优化操作。用/O2生成代码针对执行速度进行优化。生成代码的长度会很长但是执行效率显著提高,因为sumOfCubes内部的循环被展开并且向量化了。有一个概念很重要,必须理解:如果不把cube函数内联就不能进行向量化。而且,不进行内联的话循环展开并不会变得高效。Figure3 显示了生成的汇编代码的流程图。这个流程图对x86和x86-64架构都适用。
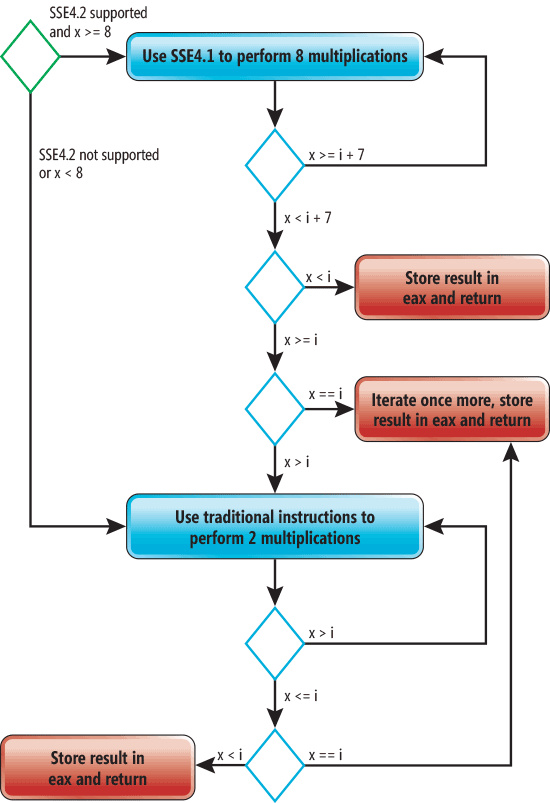
图3 sumOfCubes流程图
在Figure3中,绿色的菱形代表开始点,红色矩形代表结束点。蓝色菱形代表在运行时作为sumOfCubes函数中一部分而被执行的条件。如果处理器支持SSE4并且x大于等于8,就会使用SSE4指令同时执行四个乘法指令。同时把同一操作在多个值上执行的过程被称为向量化。编译器也会将循环展开,就是说循环体将会把每次迭代循环重复一次。这样做的最终效果就是八次乘法在每次迭代都会被执行。当x的值小于8时,传统的指令将会被用于执行余下的运算。注意到编译器放出了结合了三个独立结尾的循环结束点而不是一个。这将会减少跳转次数。
循环展开是重复执行循环体的过程,展开后的循环每次把未展开循环内的循环体执行不止一次。这样做的原因是可以通过减少循环控制指令的执行频率来提升性能。也许更重要的是,这样可以允许编译器进行许多其他优化工作,比如向量化。循环展开的弊端是会增加代码量和寄存器的压力。但是这可能使性能达到两位百分数级别的提升,当然这是和具体的循环体有关的。
不同于x86处理器,所有的x86-64处理器都支持SSE2.不仅如此,你可以在最新的x86-64微处理器架构上(包括Intel和AMD)通过打开/arch开关来利用AVX/AVX2指令集。打开/architecture:AVX2也会允许编译器使用FMA和BMI指令集。
当前的Visual C++编译器不支持控制循环展开。但是你可以通过使用模版结合__ forceinline关键字来模仿这一技术。你可以通过使用no_vector选项来禁用对于某个函数的自动向量化。
通过观察生成的汇编代码,如果你有足够敏锐的眼睛的话你会注意到代码还有少许优化空间。但是,编译器已经做了很多工作了,并且不会再花更多的时间分析代码和进行一些无关紧要的优化。
SumOfCubes(原文是someOfCubes,应该是写错了——译者注)不是唯一一个循环被展开的函数。如果你修改代码让m作为参数而不是n,编译器将不能对代码进行估计,因此必须放出其代码。在这种情况下,循环被展开了两次。
最后我要讨论的优化是循环不变量代码移动(loop-invariant code motion)。考虑如下代码:
int sum(int x) {
int result = 0;
int count = 0;
for (int i = 1; i <= x; ++i) {
++count;
result += i;
}
printf("%d", count);
return result;
}
这里唯一的改变是增加了一个变量并且在每次循环进行自增,然后打印。不难看出这段代码可以通过把变量count的自增移出循环来优化。也就是说,我可以直接把x的值赋给变量count。这种优化被称为循环不变量代码移动(loop-invariant code motion)。循环不变量部分清楚的表明这项技术只能用于其代码不依赖于任何循环之前的表达式的情况。
那么这里有一个问题:如果你自己来进行这项优化,生成的代码可能在某些情况下会导致性能下降。能发现为什么吗?考虑x为非正数的情况。循环将不被执行,这意味着未被手动优化的代码中count不会被访问。但是,在我们手动优化过的代码中在循环外进行了一次不必要的赋值操作,把x赋给了count。更甚者,如果x是负数,count就会拥有错误的值。程序员和编译器都容易受到这种陷阱的影响。所幸Visual C++编译器足够聪明地在赋值之前加上了循环条件,这样可以对所有x的值都生成性能有所提升的代码。
综上所述,如果你既不是编译器也不是编译器优化方面的专家,你应该避免仅仅因为想让代码更快而进行手工修改。管住你的手并且相信编译器将会优化你的代码。
控制优化
除了/O1,/O2,和/Ox编译开关,你还可以使用控制优化编译来达到让某个函数优化的目的,其形式如下:
#pragma optimize( "[optimization-list]", {on | off} )
[optimization-list]可以为空或者一个或多个紧跟的值:g,s,t和y。分别对应编译器开关/Og,/Os,/Ot和/Oy.
空列表和off参数会让所有的优化都被关闭,不管之前的编译器开关是否被打开。空列表和on参数会让之前打开的编译器开关生效。
/Og开关启用全局优化,全局优化只作用域那些通过表面分析就可以被优化的函数上,而这些函数内部调用的其他函数则不会被优化。如果(链接时代码生成)LTCG被启用,/Og允许代码全局优化(WPO)。
当你需要让不同的函数进行不同的优化时,比如一些进行空间尺寸优化而另一些进行执行速度优化,那么优化编译参数就很有用了。但是如果真的想达到那种粒度的控制,你应该考虑性能分析引导优化(PGO),就是通过对运行测量代码时的行为信息进行记录,然后使用这一纪录对代码进行优化的过程。编译器使用性能分析来决定怎样优化代码。Visual Studio提供了必要的工具,来将这一技术同时应用于本机代码和托管代码上。
.NET中的优化
在.NET的编译模型中没有链接器。但是有一个源代码编译器(C# compiler)和即时编译器(JIT compiler),源代码编译器只进行很小的一部分优化。比如它不会执行函数内联和循环优化。而这些优化是由即时编译器执行的。在4.5以前的所有.NET Framework JIT都不支持SIMD指令集。但是.NET Framework 4.5.1和之后的版本都装有支持SIMD的即时编译器,被称为RyuJIT。
从优化能力上来讲RyuJIT和Visual C++有什么不同呢?因为RyuJIT是在运行时完成其工作的,所以它可以完成一些Visual C++不能完成的工作。比如在运行时,RyuJIT可能会判定,在这次程序的运行中一个if语句的条件永远不会为true,所以就可以将它移除。RyuJIT也可以利用他所运行的处理器的能力。比如如果处理器支持SSE4.1,即时编译器就会只写出sumOfCubes函数的SSE4.1指令,让生成打的代码更加紧凑。但是它不能花更多的时间来优化代码,因为即时编译所花的时间会影响到程序的性能。另一方面,Visual C++编译器可以花更多的时间寻找和利用更多恰当的优化机会。微软新推出了一项称为.NET Native的全新技术,允许你使用Visual C++编译器后端对托管代码(Managed Code)进行编译和优化,并形成自包含的独立可执行程序。当下这项技术只支持Windows Store apps。
在当前控制托管代码的能力是很有限的。C#和VB编译器只允许使用/optimize编译器开关打开或者关闭优化功能。为了控制即时编译优化,你可以在方法上使用System.Runtime.CompilerServices.MethodImpl属性和MethodImplOptions中指定的选项。NoOptimization选项可以关闭优化,NoInlining阻止方法被内联,AggressiveInlining (.NET 4.5)选项推荐(不仅仅是提示)即时编译器将一个方法内联。
结语
本文中提到的所有优化功能都会显著地将你的代码效率提升两位百分数级别,并且Visual C++编译器支持所有这些优化。重要的是这些技术能够在应用之后,带来其他更多的优化。本文绝不敢奢望能够对Visual C++编译器的优化工作进行一次综合全面的讨论。但是我希望通过本文可以让你领会编译器的精妙。Visual C++可以做比这多得多的事情,所以敬请期待Part2。
更多信息请查看IT技术专栏
版权所有:易贤网